
在分布式系統中,經常會碰到的技術名詞一般有多副本、數據分區、一致性算法、事務等,這些技術在分布式系統設計中都是非常重要的,CEOPA想通過本文對分布式系統的可靠性、可擴展性和可維護性特性的討論,描述這些技術解決的問題,希望能夠幫到大家。

可靠性
指的是在任何情況下,系統正常工作的能力。如果一個系統在發生任何異常時,都能正常的工作,那么系統是完全可靠的。現實中,異常種類很多,有的往往難以事先避免,因此,了解可能的異常并分析如何在異常發生時快速恢復是非常重要的。一般地,異常包括硬件異常,軟件異常和人為異常。
硬件異常
硬件異常種類很多,硬盤,電源等任意一個部件的損壞,都可能導致服務器不能正常的工作。通常這類異常難以避免,但是,我們可以通過一些技術手段來實現異常發生后的快速恢復,不管是從軟件角度還是硬件角度,基本的解決思路都是冗余。從硬件角度來講,我們可以通過單機冗余多份硬件,當其中某個硬件發生異常時,可以快速地用好的硬件替換掉故障的硬件,這種方式的硬件冗余對于數據中心級的故障是沒有作用的;
從軟件角度來講,我們可以通過多副本(Replication)來實現快速恢復,當某臺服務器硬件異常時,可以在軟件層面將流量導入到新的副本上(實際上也有硬件冗余,但這種方式更為靈活)。
除了Replication之外,有時候為了減少單臺服務器故障對所有用戶的影響,可以對用戶數據做分區(Partition)。單臺服務器只存某一部分用戶的數據,這樣單機故障就只會影響一部分用戶了。引入多副本(Replication)后,如何保證多副本的數據的一致性又成了一個問題。Paxos和Raft算法就是為了解決這類問題。

軟件異常
軟件異常一般指的是系統的bug,這里面不僅包括自己寫的系統的bug,也包括依賴的服務系統的bug。軟件異常同樣也是不能完全避免的,因此,在發生軟件異常時,也需要有快速恢復的手段,通常有三種方法:1. 通過調整軟件已有的配置參數,規避問題
2. 重啟軟件或者依賴的服務,消除異常狀態
3. 直接修復bug,并升級版本
人為異常
不管是軟件本身,還是軟件所運行的服務器,都是由人來管理的,但人是會犯錯誤的,有時候會執行錯誤的命令導致系統不能正常工作,其中比較致命的錯誤可能就是刪掉某臺服務器的數據了。在這種情況下為了能快速地恢復,通常也是采用多副本(Replication)的思路,來避免問題。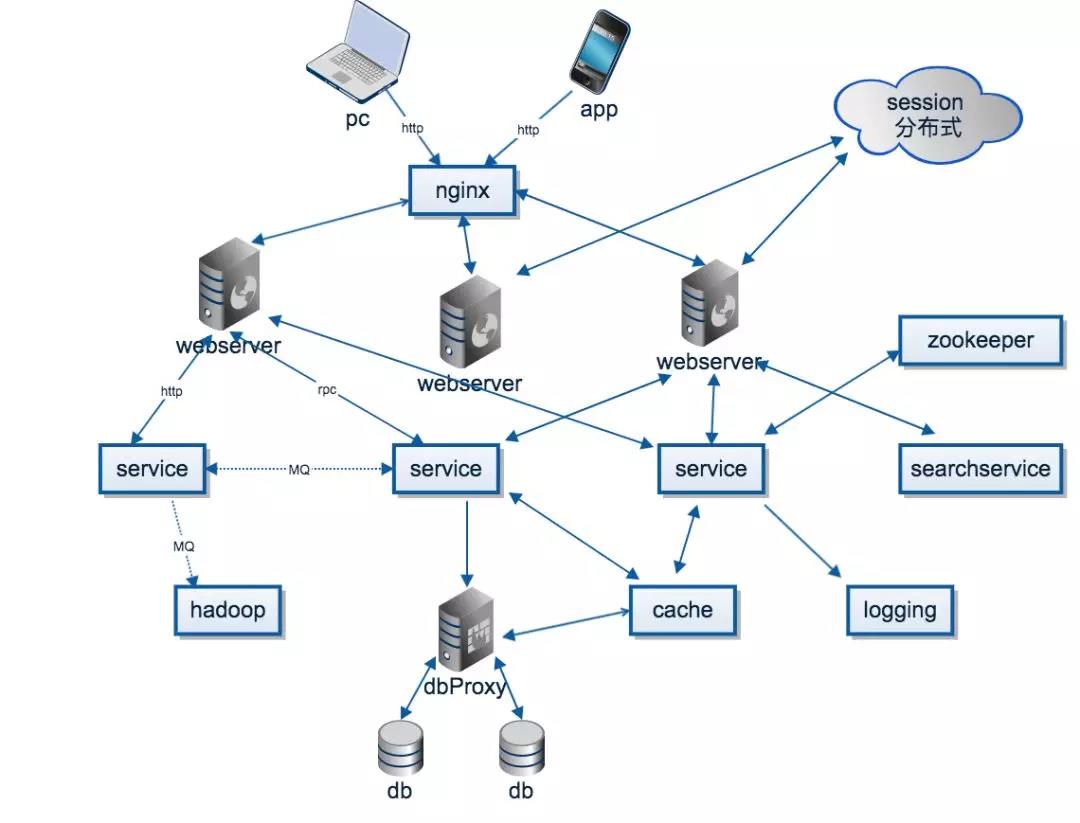
擴展性
系統的工作負載通常不是一成不變的,當工作負載增加時,往往可以通過增加機器資源來保持性能不變。需要增加機器數量的多少是由系統的擴展性來決定的,擴展性越好的系統,需要增加的機器資源越少。最完美的擴展性是線性擴展性,即工作負載擴大為原來N倍的時候,只需要加N倍的機器,就能夠保持性能不變,最差的擴展性則是沒有擴展性,即工作負載擴大為原來N倍時,即使加再多的機器,也無法保持性能和原來一樣。
擴展通常是兩種思路,一是垂直擴展,即使用更好的機器替換現有的機器,二是水平擴展,即使用更多的機器。
對于垂直擴展,其優點是對業務是無影響的,缺點是更好的機器是很貴的。通常是一分錢一分貨,而十分錢只能買到兩分貨,且現實中總有單機裝不下的數據量,此時垂直擴展自然就無法實施了。
對于水平擴展,通常需要軟件層面的配合。對于無狀態的系統,通常只要在新加的機器上部署上需要擴展的系統;對于有狀態的系統,一般指的是存儲系統,通常會將數據分區Partition。這樣新加的機器才能通過遷移Partition的方式,從老的機器上遷移數據以及對應的工作負載出來。水平擴展的優點是使用的都是相對廉價的服務器,能節約成本,但在軟件層面需要做大量的工作,包括Partition的管理,遷移,負載均衡等。
可維護性
可維護性的好壞決定了系統是否能夠長久的發展,一個可維護性不好的系統,會給運維和開發人員帶來很多不便。對于運維人員來講,可維護性指的是系統是否支持常用的運維手段,良好的文檔等等。而對于開發人員來講,主要分為內核開發以及使用該系統的業務開發,對于業務開發,維護性指的是系統是否有良好的接口,方便業務使用。